

Introducing texted – a text editor for LLMs
...what happens when LLMs edit text like humans?


Seeing LLMs struggle with file edits sometimes degenerates into this:
Model: let me edit the file to remove comments.
Tool(edit_file): old_str is not present in the file
Model: I see there is an issue with editing the file, let me try again
Tool(edit_file): old_str and new_str must be different
Model: Let me try a different approach
Tool(bash): sed -i "s/\"old_str\\"/new_str" file.go
Unexpected EOF while looking for matching `"'Model: Let me rewrite the entire file from scratch
This got me thinking – what if instead of `sed` there was a more powerful tool that the LLM could use?
One that is easier to understand.
The desire to get an answer was so strong, I had to get to work right away.
The result is texted, a headless, scriptable text editor meant to be used by LLMs (or you, if you don’t like writing sed scripts).
After 7 hours and $50 in Anthropic credits, the first version came out of the oven and still steaming, I plugged into the Claude Code:
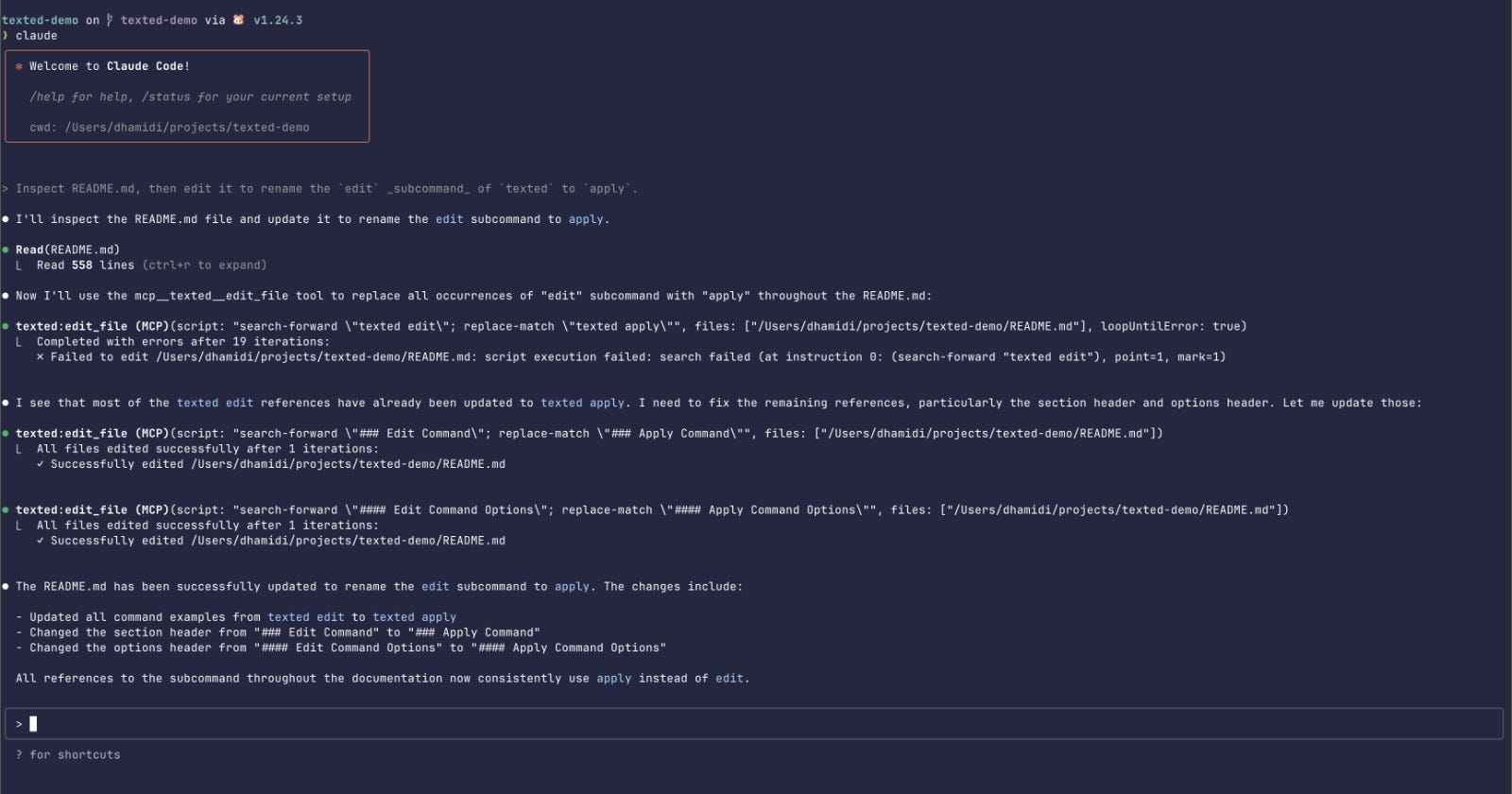
To my surprise: it worked!
I mean, edited a file successfully without reading it more than once – that’s a win already.
But more interestingly, it provided some evidence that LLMs can handle made up languages just fine, which opens up all kind of interesting doors
Designing texted
Quick, what programming language is:
has been around for 40 years,
is specialized for text editing,
and easy on the eyes.
It can’t be Vimscript - on account of not being “easy on the eyes”.
Nor sed.
So that left Emacs Lisp.
Sure, using Emacs as the backend to texted would have been the more capable solution.
But also more cumbersome to integrate, and definitely not something everyone wants to have installed on their machine.
Since code is cheap, I settled on implementing a subset of Emacs Lisp that is not turing-complete to guarantee termination of the edit operations.
All functions implemented by texted follow the elisp functions provided by Emacs, so that the LLM can leverage its existing knowledge.
For funsies, I threw in shell-like syntax which is a bit easier to type, so that:
search-forward "func main"
replace-match "func run"is the same as writing:
(search-forward "func main")
(replace-match "func run")And since the world doesn’t run on Lisp 🥲 and we're not implementing an actual programming language, instructions can also be easily serialized as JSON to integrate with other systems:
["search-forward", "func main"]
["replace-match", "func run"]Guess which format the LLM ended up preferring?
Hint: it’s not S-expressions.
The spec
With these ideas in mind, I wrote a spec.
A rough outline of what I want, why I want it how the pieces fit together.
This is were experience comes into play: I’ve implemented Lisp interpreters before, so I knew what to look for and how to paint in broad strokes:
In fact, the regular texted script parser just uses a specialized reader:
Leading whitespace is stripped
If the next character is
(, read a regular S-expression list, ignoring whitespace between elements.Otherwise build a list reading invoking the reader repeatedly until a single
\nis encountered.
If you know about the Lisp reader, the new syntax is easy to describe in terms of the differences to the regular reader.
Otherwise…its more difficult.
Driving Claude mad
With the spec in hand, it was mostly smooth sailing – in projects like this I’m still trying to see how far I can push my process to have LLMs write all of the code.
Here are the parts that needed manual intervention still:
designing and adjusting expectations in the made-up XML integration tests,
defining desired behavior in the CLI spec,
helping it with inconsistent method naming in the Go MCP library I’m using
designing the code for the pseudo-Lisp implementation
Let’s talk about quality
My definition of quality is this:
Does it meet expectations?
“it” referring to texted here, and “expectations” referring to the expectations of different roles:
as a user of the software: does it do what it says on the tin?
as a developer of the software: can I keep evolving it without breaking things?
The current implementation satisfies both.
Yes, the interpreter is far from optimal – more time could make it more performant, the code “cleaner”, and allow implementing more Lisp features.
None of these things are relevant to finding out whether LLMs work better with an LLM-friendly text editor.
What’s next
I’ll be using texted over the next days and weeks to see what needs improvement.
Claude at least seems to be pretty capable at using it, but I can already see that the set of functions provided by texted is not a good fit.
To get the current selection, you need to do something like this:
(buffer-substring (region-beginning) (region-end))This would be less error-prone and shorter:
(region-text)There are more such inconsistencies and improvements, and only extended use will uncover them.